
A Digital Library Everywhere
The researcher is sitting in the café, researching ants on her phone. She goes to the digital library portal and types in "formica"
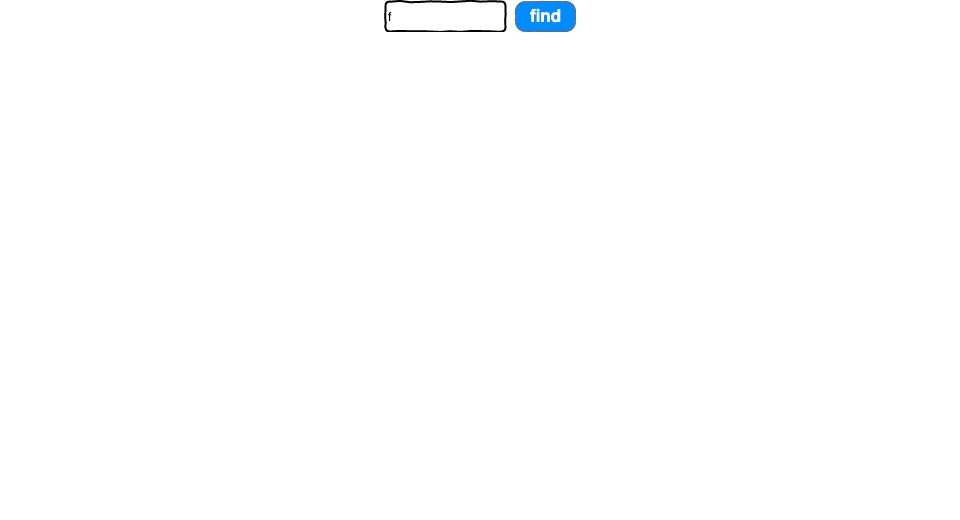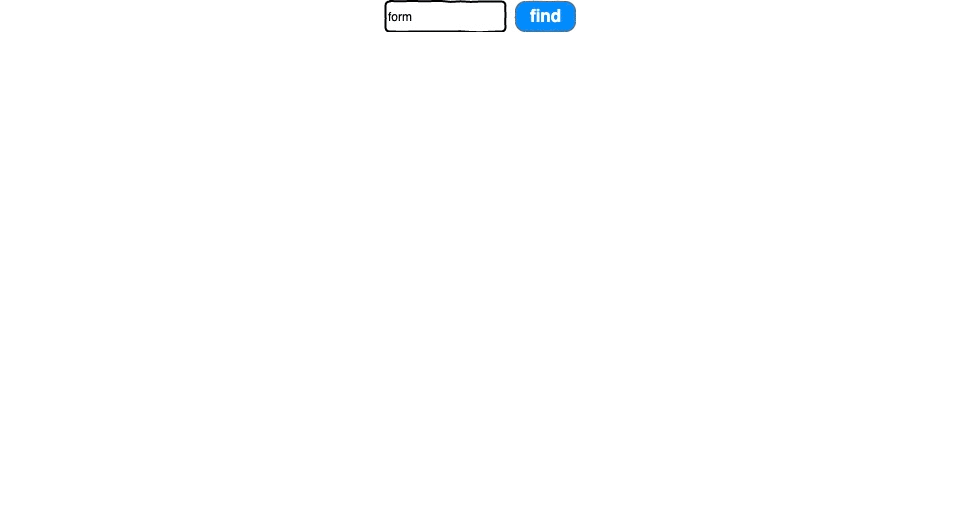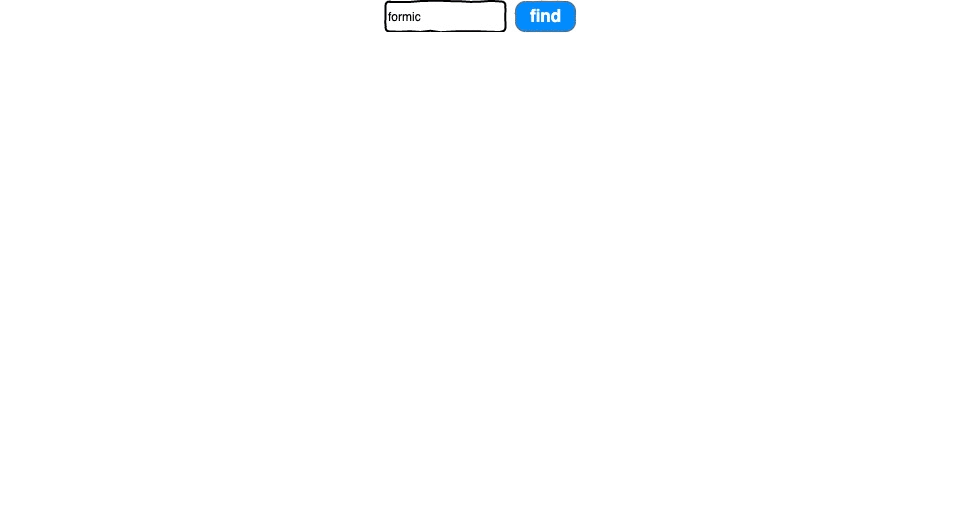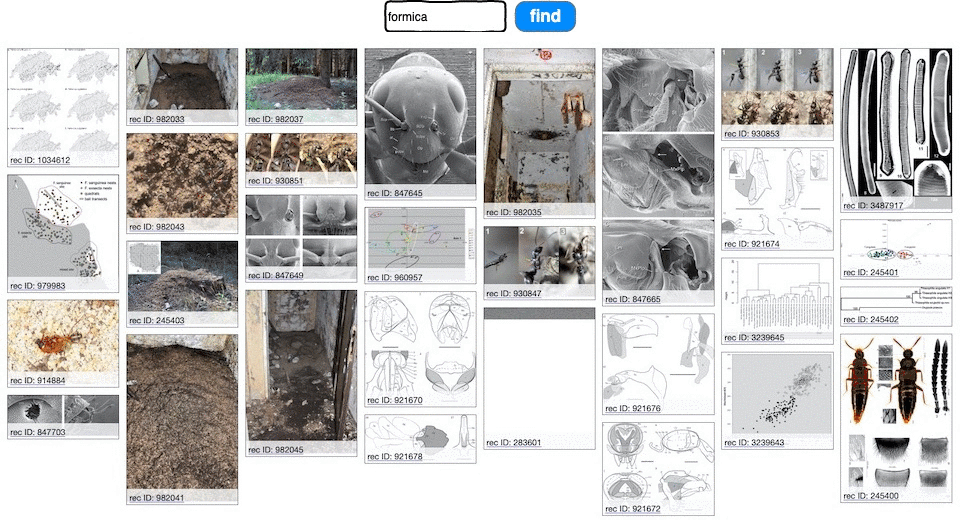
She gets back images, 3D scans of the holotype, and spectrograms and even mp3s of ant sounds.

All this is possible because you added your research paper to the digital library.1 When you uploaded your born-digital PDF, it triggered a process that extracted the key facts from your paper with the help of semantic tags embedded in the text. The facts were then added to TreatmentBank and also to the Global Biodiversity Information Facility (GBIF). From the TreatmentBank, the facts and any images (photographs, charts, diagrams) were also uploaded to Zenodo where they will be preserved for posterity, backed by the infrastructure of CERN and the European Union. When being uplooaded to Zenodo, each one of the discrete items were assigned a unique digital object identifier (DOI), a permanent ID that would identify them forever. In turn, all that data became searchable by Zenodeo, a nodejs-driven API, and the binary files became findable via Ocellus, a Zenodeo-driven web application. Since you also uploaded the associated 3D scans of specimens and their sounds, they too became findable.
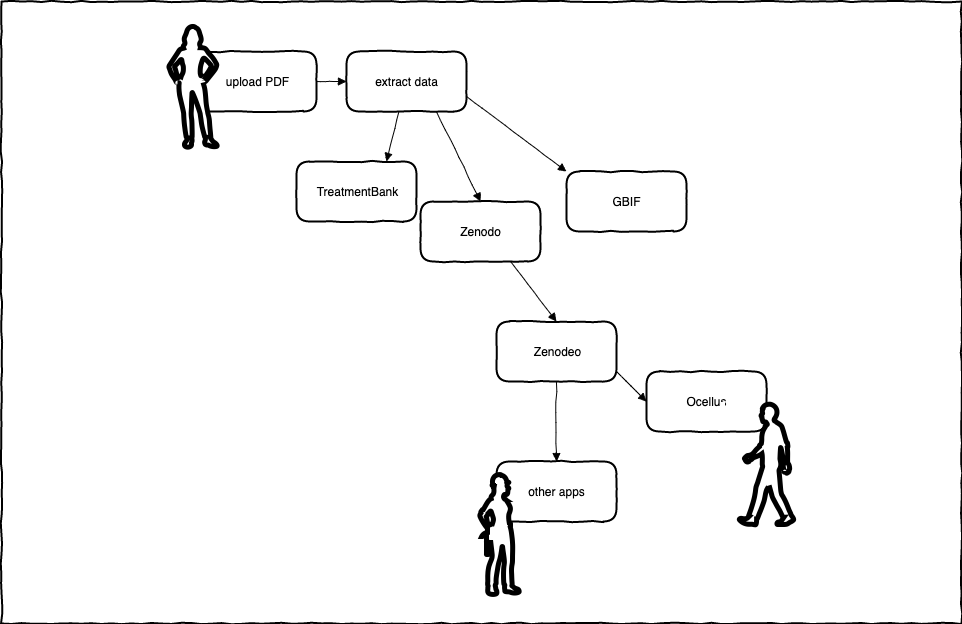
- While the resource described in this article is fictitious, all the parts that make up this resource are very real and already exist. By all measures, TreatmentBank is already the world's largest public domain database of taxonomic treatments extracted from text-mined biodiversity papers, and is providing continuous data to Zenodo, BLR, and GBIF. Ocellus, and Zenodeo, the API that powers Ocellus, already exist and are being continuously improved. ↩